羊年到来之际,我院研究团队成功创建基于仿脑计算的多物体识别系统。该系统基于仿脑计算的基本原理,采用国际上先进的机器视觉理论和深度学习的相关模型,并通过CPU和GPU异构计算得以实现,识别率高、运算速度快。其识别工作在实现原理上有别于现有特殊物体和形状的识别,如人脸,掌纹和车牌等,而是基于仿生视觉的新方法。
以往的图像识别技术过分强调和依赖由人为指定的图像特征的提取。而大脑的发育过程是一个自适应的特征提取过程。视觉信号从视网膜到IT脑区要经历至少10层以上的神经网络处理,其中还有很多反馈机制。在IT脑区中,同一个物体,在不同的角度、大小、光照等条件下,会激发相对固定的一族神经元的电活动,给大脑带来对这一物体的认知基础。
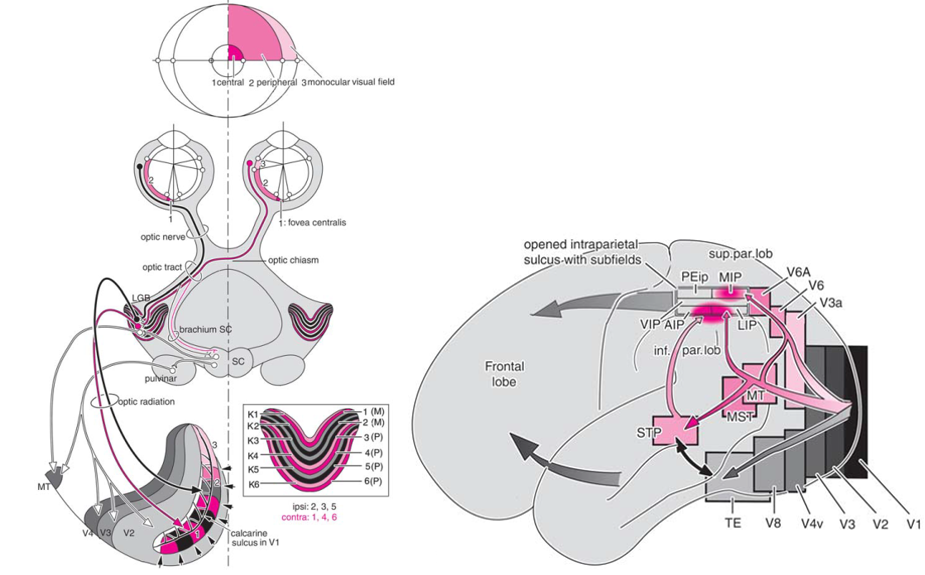
我们的多物体识别工作模拟人的视觉系统处理信息的过程,建立了若干层神经网络,逐步的视觉信息做相应的处理,最终达到可以使其具有识别各种形状的物体的能力。
整个训练过程分两部分,第一部分是无标签的“自由学习”过程,如同小孩出生之后,观察各种形状颜色的物体,这一过程并不需要告诉它物体是什么东西,只是通过不断的观察,在网络中形成对常见的简单形状和复杂形状的敏感性,也就是只需要它对所见到的各种物品有一定的“印象”,形成一个通用的用于描述各种物体的形状特征集。
第二部分是有标签的指导学习,在这一过程中,所有图片被告知是某种物体或者不是某种物体,这样,通过对不同物体所具有的形状特征集的差别结合一个分类器,就可以对某一种或几种特定物体进行区分。
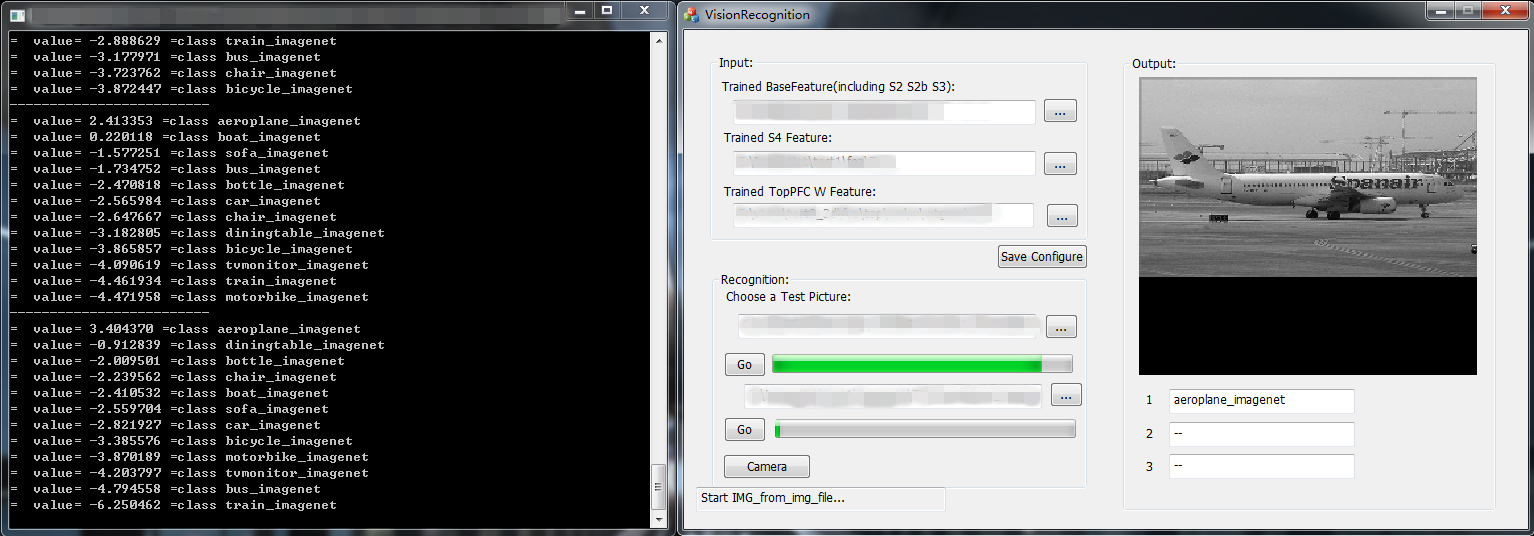
基于仿脑计算的多物体识别系统具有深刻而广泛的应用。例如,视频的语义标注在移动互联网时代具有巨大的市场需求,但至今为止,尚不令人满意。图像和视频的搜索十分不便。该系统将有助于视频的语义标注自动化,实现既快又准的语义标注,实现图像和视频的语义搜索功能。再如,由于该系统采用仿脑计算技术,可以和其它仿脑技术的功能模块对接,实现更高级的功能(例如和眼动功能模块对接,实现指定运动目标的跟踪)。
伴随GPU的普及,智能手机也将能使用基于仿脑计算的多物体识别技术。虽然该技术的训练学习系统需要工作站来完成,但训练好的“大脑”可以在带有GPU功能的智能手机上快速运行。例如基于对各种手势的识别训练,可以生成类似于“石头剪子布”这样的手机真人互动游戏。
目前,基于仿脑计算的多物体识别系统还在进一步完善中。我们期待和大脑的物体定位、眼动功能模块结合,实现更强大的功能。