毫无疑问,现在深度学习的代表性产物AlphaGo能赢任何一位围棋高手(当然,你如果不服可以去挑战一下~~~)。不过,一条不懂围棋的狗可以自由的穿梭于草地、丛林、社区,有着强大策略分析能力的AlphaGo能驱动一个生物角色做到自由运动吗?

用深度学习的手法驱动虚拟生物角色运动是一件极富挑战性的工作,今年爱丁堡大学 Daniel Holden,Taku Komura 和 Method Studios 的 Jun Saito 三位研究者提出 “Phase-Functioned Neural Networks”(简称 PFNN),效果十分出彩,并在ACM SIGGRAPH 大会上展示。
笔者以为,PFNN的结构新奇,把深度学习运用的十分巧妙,可以给我们奋斗在深度学习第一线的研究者们带来很多启示。毕竟,我们习惯了拿来一个深层的卷积神经网络,左手摁进数据X,右手拿着标签Y,等着网络层层抽feature完成任务,Boring! Very boring!
如果让我们完成用神经网络来驱动一个虚拟人物在虚拟的场景中以逼真的姿态实时运动,还要完成攀爬斜坡、越过障碍,做到根据用户输入加速、转身、改变步态,该如何下手呢?要用CNN吗?要用LSTM吗?要堆叠多少层?想想都头痛……
我想能啃下这块硬骨头的人,在搞深度学习的人群当中微乎其微。言归正传,我们来学习一下PFNN的结构,看看三位大牛是怎么倚天屠龙的!

在我们以往的经验中,训练神经网络就是定义网络结构和超参数,定义损失函数,输入大量训练样本X、Y,通过梯度下降找出连接权值w,完成任务!实际上要用神经网络解决具体的问题,真正的技巧在于根据问题的不同来改变网络的结构,而不是暴力的灌数据,加神经元,加层。PFNN的神经网络部分只有两个隐藏层,每层神经元512个,没有卷积操作,没有LSTM。
这样简单的网络怎么完成这么复杂的,而且是时序相关的任务呢?其核心在于PFNN的网络连接权值并不是固定的,而是根据一个被称为Phase-Function的输出动态调整的。我们常用的神经网络模型在训练完成之后,其参数便固定下来,如果参数个数为N,那么这组参数可以表示为N维空间中的一个点,而FPNN的网络参数是N维空间中的一个一维流形(可以简单理解为高维空间里的一条曲线),在不同的时刻,角色有不同的姿势,我们会把这些因素综合起来,得到角色的一个相位,然后根据这个相位,在参数所在的一维流形上取一个点,代表这个点的N个参数就是神经网络的连接权值在这个时刻的取值。随着角色的运动连续变化,相位不断调整,我们在一维流形上连续的取不同的点,就得到了一个连接权值不断循环变化的神经网络。
怎么样,是不是觉得很优(meng)雅(quan)?还是来详述一下这个过程吧——
第一步,准备数据。
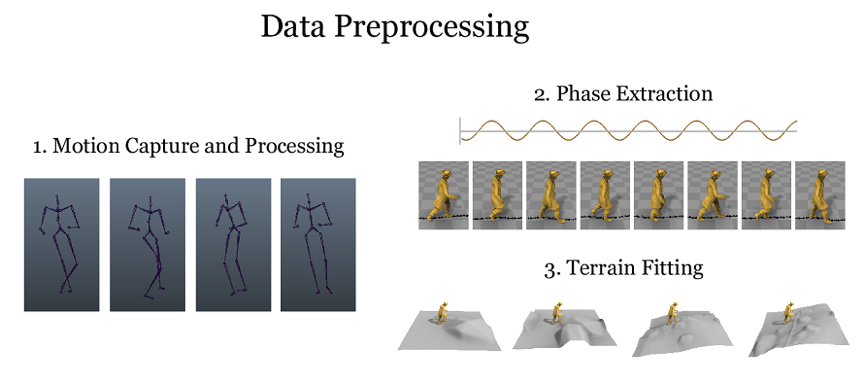
首先是motion capture(运动捕捉)。就是找一个演员,让其在身上穿戴上一些有定位、记录等功能的各种硬件,以不同的步态(例如正常走路、小跑、跳跃等)在不同的地形上运动,并记录下各个关节的运动情况。进一步我们还要对这些运动数据打上标签(这部分标签并不是我们做图像分类的正、负样本标签),来标注哪些时刻左脚着地、右脚着地,步态是哪种类型,运动的轨迹,角色前进的方向,等等。这些标签有些可以自动生成,有些要靠人为记录。有一点要提醒大家注意,所谓相位,就是在这个阶段标定的,我们可以将某次右脚着地点的相位记录为0,下一次左脚着地记录为π,再下次右脚着地记录为2π,依次进行。这样我们就有了角色运动的数据,这些数据就可以赋予到一个虚拟动画角色上。
然后,我们要去生成虚拟的地形来适配以上生成的运动数据,简单来讲,我们上一步记录了角色的运动,但并没有记录地形,我们要用虚拟的游戏中的地形(多边形的组合)来适配角色的运动数据,做到看上去不出错误、自然协调,例如角色脚步着地时要确保地形与脚部关节贴合,地形有障碍时候角色做出的是跳跃或避开等恰当的反应,并且做到生成的地形在计算量与细节复杂程度之间做一个很好的折中。
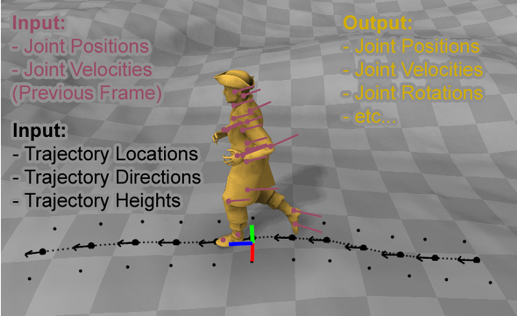
完成前面两项之后,要把角色运动数据和地形数据做进一步处理。简单来讲,输入数据X要包含角色轨迹的位置、方向、地形高度,步态,角色前一帧的各个关节的位置、速度等,输出数据Y包含了当前帧角色各个关节的位置、速度、角度,角色根节点的位置、角度,角色的相位变化情况,下一帧角色轨迹的位置、方向等等。这样,我们就有了训练神经网络所需的数据。
第二步,训练网络。
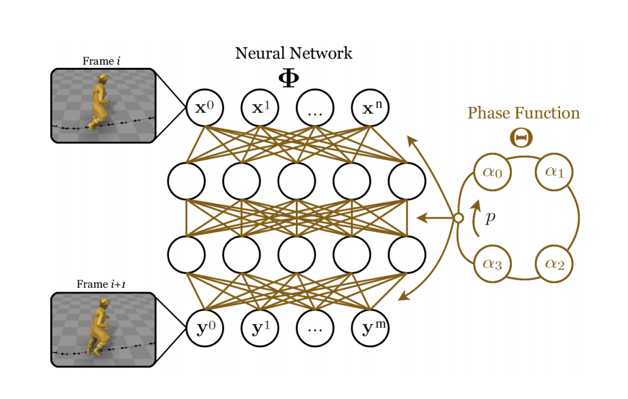
如图所示,PFNN的神经网络部分记为Φ,只有两个隐藏层,每个隐藏层神经元为512个,

其中,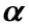 代表神经网络的参数。
代表神经网络的参数。
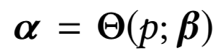
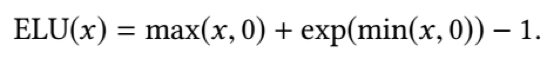
图右侧的Phase Function为相位处理函数。实质上,这个函数并没有多复杂,只是做了样条曲线函数在四种相位之间做了差值,使得生成的神经网络参数可以动态的、循环的调整。
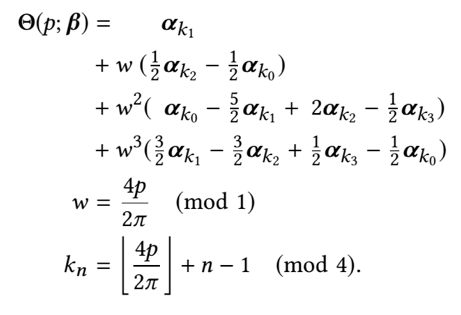
其中,p为相位,可以根据神经网络部分的输出确定。
损失函数定义为
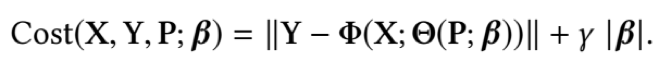


有了网络结构,定义好损失函数,开始train,可以喝咖啡去了……
第三步,测试运行。

训练好网络以后,用户便可以手拿游戏手柄,控制虚拟世界里面的游戏角色运动了,在这个阶段,仍然有需要调整的地方,用户的游戏手柄输入会改变角色的运动方向、速度等,由于惯性,角色响应用户的速度跟运动的优雅、自然程度之间有矛盾,这时候可以用参数在这两者之间做一个协调。这个阶段可以做的调整还有很多,在此就不一一介绍了。
以上只是根据论文简单的介绍了PFNN的方法,这项工程并不容易,需要注意的细节还有很多。作者在论文中也将PFNN与用其他类型的神经网络和传统方法在最终效果、训练时间、运行速度上做了对比,读者如果感兴趣可以参照论文仔细研读。
总之,三位大牛的工作十分exciting。对我们从事深度学习的人来讲富有启发,希望大家能从中学到有用知识,真正学会“设计”你的神经网络。
参考文献 :
Daniel Holden,Taku Komura ,Jun Saito. Phase-Functioned Neural Networks for Character Control.
本文为原创编译,转载请注明出处