
来源:venturebeat
编辑:梦佳、小匀
【新智元导读】常识一直是困扰AI发展的难解谜题。就算AI能够在围棋比赛中战胜人类,但机智如GPT-3却不能理解「太阳有几只眼睛」这种问题是反常识的。而最近,谷歌DeepMind、帝国理工和剑桥的研究人员开创性地提出,AI可以从动物身上学习常识!今后可以像训练小狗一样训练智能体了。
Geoffery Hinton曾经预言,十年内,我们将研发出具有常识的计算机。这些计算机并没有灵魂,它们只是具备了人类世界如何运作的知识,熟悉我们的惯例。它们知道炉子是热的,知道人们通常不会买12台烤箱等等。常识是什么?最通俗的解释是指与生俱来、毋须特别学习的判断能力,或是众人皆知、无须解释或加以论证的知识。数十年来,常识是一直以来困扰着AI发展的难解谜题,就算AI能够在围棋比赛和Atari游戏中战胜人类,但聪明如GPT-3却不能理解「太阳有几只眼睛」这种问题是违背常识的。在如何让AI拥有常识的漫长求索之路上,研究人员往往会从婴幼儿身上入手,从神经科学和行为科学中寻找灵感和答案。而最近,谷歌 DeepMind、伦敦帝国理工学院和剑桥大学的人工智能研究人员开创性地提出,AI可以从动物身上学习常识!这其实不是第一次提出AI应该向动物学习了,AI大神Yann LeCun曾表示,「家猫都比最聪明的机器有常识得多。」人的常识是建立在许多其他动物所拥有的一系列基本能力之上的,而通过深度强化学习,智能体或许可以从动物身上学到很多东西。该研究小组发表在《 CellPress Reviews 》杂志上的论文《人工智能与动物常识》(Artificial Intelligence and the Common Sense of Animals)写道: 「动物认知提供了一个很好理解的,非语言的,智能行为的概要,提出了作为评估基准的实验方法,它以指导环境和任务设计。」
在著名的伊索寓言中,试验者要求鸟类将物体投入装有水和浮动食物的玻璃管中,提升水位,来获取食物。
训练动物的过程,通常包含着目标和奖励。比如说训练小狗,动作做的对,就奖励他食物,这和运用深度强化学习训练智能体的方式有相似之处。相比之下,其他形式的人工智能,例如助手 Alexa 或 Siri,就不具备这种类似于在迷宫中搜索奖励或食物的能力。此前,认知行为科学家已经发现,动物的智力水平比先前设想的要高,包括海鸦的复仇心理和海豚的自我意识。(小孩子要长到一岁半时才能有自我意识,才能认出镜子里自己的形象)很多时候,动物甚至会采取欺骗或者诡计来达成自己的目的。例如,黑猩猩把目光从渴望得到的东西上移开,来迷惑竞争对手,而松鸦会假装把食物储存在虚假的地点来保护它们的隐秘储藏处。实验中,研究人员将测试场景中的动物和强化学习智能体进行类比,用一种新的方法来测试人工智能系统的认知能力。《人工智能与动物常识》一文详细讲述了对鸟类和灵长类动物的认知实验。这个实验最初的目的是确定鸟类是否能够区分与任务相关的功能性和非功能性物体,并探索它们对所涉及的因果关系的理解程度。
松鼠会想办法撬开坚果的外壳,获取里面的果实;某些鹦鹉也十分擅长从各种容器中提取食物;当看到裂缝,孔洞或破裂之类的东西时,有的动物会作出「我要打开它」的反应。这是为什么?这是它们的意识中有了「因果」这一概念。也就是,「只要我打开它,就会有食物。」而这,也是AI要训练的部分。作者联想到训练动物的方法,发现「试错」是十分奏效的。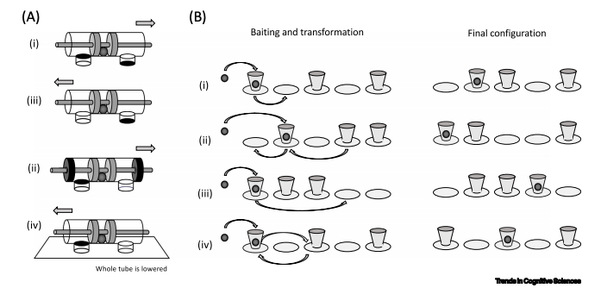
来源于动物认知实验,用来测试强化学习智能体获取的常识
(A)使用四种不同形式的管道测试物理认知能力。如果棍子从错误的一端拔出,食物就会丢失。通过试错来应对不同情况(i),只学会了表面联想的动物,在迁移任务[变异]中往往表现不佳 (ii)至(iv))],而已获得因果理解的动物往往在第一次试验中表现良好。(B)用一个看不见的位移任务来测试对物体永久性的理解。在用食物做诱饵后,杯子被移动至右边所示的最终排布。然后,动物要选择盛有食物的杯子。当然,杯子是不透明的,但是食物的位置能够清晰地显示出来。能够理解这种看不见的位移的动物在所有四种不同情况中都表现得很好,即使它以前从未见过相关的物体。而足够逼真的3D世界模拟,是训练的必要条件,包括可能会破裂或被撬开的贝壳,无法拧开或撬开的瓶盖,可撕开的包装盒等等物体。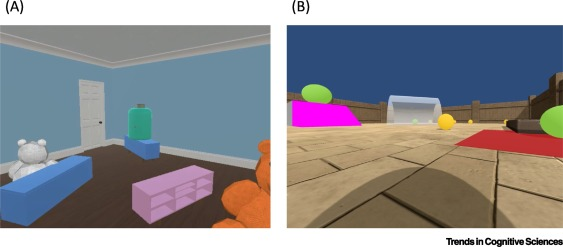
训练RL智能体的3D环境智能体可以在场景中移动,并推动物体。在游戏室的环境中,智能体也可以拿起物品并把它们放下,它通过成功地执行自然语言指令获得奖励,比如「把一个泰迪熊放在一个蓝色的方块上」。在动物AI环境中,智能体通过移动绿色球体获得奖励。更为有趣的是,为了精准模仿动物与食物的因果关系。研究人员将绿色物体定位为「食物」,当被触摸时会产生积极的奖励,然后就像被吃掉一样消失。总结来说,常识是人类独有的吗?研究人员认为,并不是,常识是取决于一些基本概念的。比如,眼前的物体是什么?它会占据多大空间?以及因果之间的关系等等。而且,这些理解被深深地刻进头脑,并不会随着时间的推移而发生改变。然而,动物所表现出来的常识,很可能就包含对奖励的认知。「如何构建这样的人工智能技术仍然有待解答。但是我们提倡一种方法,让 RL 智能体通过与丰富的虚拟环境进行扩展交互来获得所需的东西。」因此,通过适当的任务训练智能体,很可能就能为AI赋予常识。当然,常识也不仅仅是这些。物理学只是常识的一个领域。我们忽略了一些心理学概念(如相信某件事或表达出不开心)以及相关的常识性社会概念(如与某人某物在一起,或给予某人某物)。物理上讲,上述实验的重点是固体。更完整的还应该包括液体(水坑、溪流、瓶中的酒)、气态物质(烟、雾、火焰)和颗粒物(土壤、沙子),甚至包括可变形物体(海绵、纸张、绳子、衣服、树叶、树枝、动物的身体)和空间(洞、门道、入口)等。从这个意义上讲,常识可以看作是一组相互关联的基本原则和抽象概念。更高更抽象的层面上,还包括类比和隐喻的运用。「理想情况下,我们希望建立一种AI技术能够把握这些(关于认知的)相互关联的原则和概念,并拥有人类层面的概括和创新能力」论文的最后写道。参考链接:
https://venturebeat.com/2020/10/25/researchers-suggest-ai-can-learn-common-sense-from-animals/
https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(20)30216-3
本文转载自:公众号新智元








