一、连续学习
连续学习(Continual Learning或CL),又称终身学习(Lifelong Learning)是指人类所具有的可持续学习的能力。目前,人工智能(AI)中的机器学习(Machine Learning或ML)还缺乏连续学习的能力,在连续学习的过程中会出现困扰AI领域长达30年之久的著名“灾难性遗忘”问题: 例如在学会了识别数字“0”和“1”之后,再学“2”和“3”的话,就会倾向于忘记之前学会的“0”和“1”。所以,现在的AI需要事前知道需要学习的类别,当遇到事先未知的类别数据时,就需要和原来的类别数据(如果保留了的话)一起重新学习。 但许多实际应用(如自动驾驶、产品推荐等)中,我们不可能知道将来会遇到怎样的新场景新产品内容,这就导致很多实际应用难以展开,或者需要付出很大的重新学习代价。
近年来,人们开始重视“灾难性遗忘”问题,并取得了一些进展。2019年,美国DARPA启动了Lifelong Learning Machines (L2M) 专项。经过这几年全球科学家们的努力,一些方法得到发展,使得“灾难性遗忘”问题这个瓶颈得到一定程度的缓解。
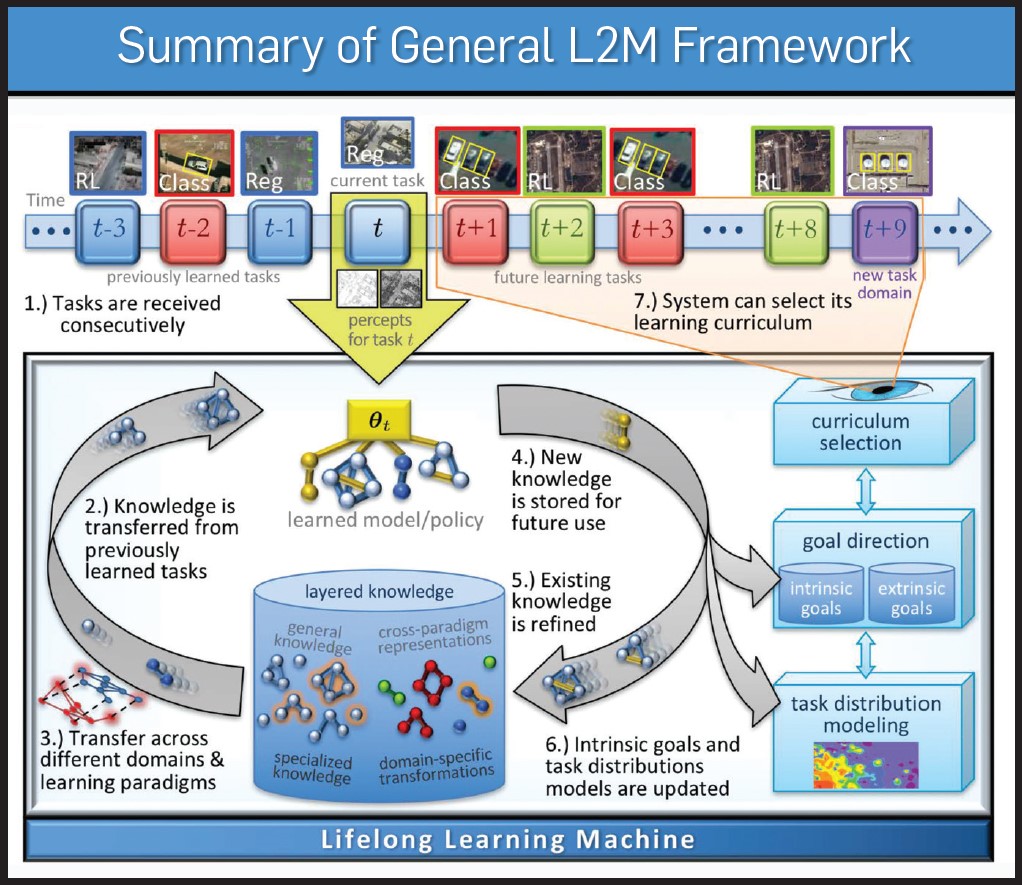
这些方法中比较著名的有LwF (Learning without Forgetting)、EWC (Elastic Weight Consolidation)、SI (Synaptic Intelligence)、 ICARL (Incremental classifier and Representation Learning)、GEM (Gradient Episodic Memory)、 OWM (Orthogonal Weight Modification)、BIR (Brain-inspired Replay) 等。我国中科院自动化所的余山研究员团队提出的基于权重正则化保护的正交权重修正方法(称为OWM方法),也取得过不错的连续学习分类效果, 有关论文发表在2019年AI顶刊《Nature Machine Intelligence》上。由于大脑具有明显的连续学习能力,这些方法的主要思路也是对大脑连续学习能力的机制的某种猜测或假设,并用机器学习的方法去实现。例如保留部分“样本”的重放思路,就是利用了大脑的短期和长期记忆能力以及长期记忆的调用与回放的可能机制。但这些方法,还都没有脱离当前AI中的核心算法:误差反向传播(BP)算法。而有趣的是:BP算法是被绝大多数脑科学研究者认为在大脑中并不存在的算法。所以这些方法并不完善,实际效果和大脑相比还相差较远。此外,这些方法还有一个明显的缺点:Sloooooo…ooooooow!所以,还难以应用,尤其难以面对在开放环境中较大规模很多类别的应用场景。
我们认为:人脑特有的概念细胞的形成是人类具有连续学习能力的核心原因。借助自主研发的大脑仿真模拟平台NiMiBrain®,我们从2017年开始对人脑概念细胞的形成机制进行了深入的研究和一系列的仿真实验。采用了多房室HH神经元模型,基于钙浓度的突触学习理论,创建了突触可塑性的简化模型和学习算法,摈弃了机器学习中的核心BP算法,实现了类脑的连续学习能力。
由于大脑仿真模拟平台NiMiBrain®具有世界一流的计算速度和便捷的图像化操作界面,NiMiBrain®赋予了我们很大的模拟实验自由空间和很高的模拟效率。 通过大量的小规模模拟实验,我们总结出了一些有关神经元群体的学习规则,称为神经元群体学习规则(NAL® Rule),并可以在现有的CPU+GPU计算设备上得到快速实现。相比前面提及的OWM方法,NAL®方法不但精度更高,速度更是快180倍以上,达到可以针对大规模数据集的应用目的。例如对于手写文字的数据集CHARACTER5378(包括3755个中文手写字和1623类世界上多种语言的Omniglot手写字母),NAL®方法能在30秒内完成连续学习,并达到91.1%的准确率,无论在速度还是精度都遥遥领先其它方法,达到了可以满足实际应用的需求!当然也支持ImageNet这样的图像数据集。

用户可以[创建项目],尝试从无到有的类别增量学习(训练)过程,并随时可以进行对学习效果的测试,包括上传自己的图片去测试,甚至可以增添自己的新类别。 无论是学习训练还是测试过程,系统可以很快返回结果,充分说明这一方法的有效性。
为促进产学研深度融合,欢迎有需求有兴趣的企业联系我们,给我们反馈信息。或许您的需求和我们提供的演示不完全一致,但我们的核心算法很可能一样能帮助到您。 我们所提出并坚持研究的类脑智能不是一句口号或一个概念,是对大脑的理解是类似于大脑的算法。Together, we can be stronger.
更多内容,请移步 http://nimibrain.cuc.edu.cn/clweb/
相关代表性成果:
1.Chen W, Du F, Wang Y, et al. A Biologically Plausible Audio-Visual Integration Model for Continual Learning[C]//2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021: 1-8.
2.Ding Y, Wang Y, Cao L. A Simplified Plasticity Model Based on Synaptic Tagging and Capture Theory: Simplified STC[J]. Frontiers in Computational Neuroscience, 2021, 15.
3.NiMiBrain. https://nimibrain.cuc.edu.cn/ . 2017.
4.曹立宏,邓雅菱. 遗忘的机器-记忆、感知与“詹妮弗·安妮斯顿神经元[M]. 电子工业出版社. 2021
5.陈雯婕,杜凤桐. 2019年国际大学生类脑计算大赛,决赛三等奖,“采用类脑SNN的视听整合实现连续学习”,2019
二、概念表征
当我们想到“狗”时,会想到这是一种特殊的动物、有尾巴、有毛、会发出“汪”声、可以当宠物等等,这是我们人脑对“狗”这个概念的一些表征。当我们把概念通过语言的形式表达出来时,则可称为概念的语义特征。自2005年,科学家发现人脑中的概念细胞以来,虽然对概念细胞的形成机制还不清楚,但主流的观点是:语言是概念细胞形成的重要条件。显然,概念的语义特征依赖于人脑的记忆、抽象和语言等高级认知功能,是心理学、神经科学、语言学等多学科研究者一直在努力研究的方向之一,也是近年来人工智能,尤其是类脑智能的前沿研究的一个重要方向。

图1 你脑中的“狗”是什么样子的?
概念语义特征的另外一个特点是个体和群体的差异性。同一个概念,对于不同年龄和文化水平的人,会有不同的个体表征差异。在不同文化和语言的背景下,同一个概念在不同人群大脑中的表征会呈现出群体性的差异。目前,国外学者已建立了多个英文版概念语义特征数据库,但尚缺乏完善的中文版概念语义特征数据库。为此,中国传媒大学的媒体融合与传播国家重点实验室团队建立了一个中文版概念语义特征数据库,共采集了1410个概念及其语义特征。论文及数据资料已在线发表于Springer Nature的《Behavior Research Methods》(https://doi.org/10.3758/s13428-020-01525-x)。希望本数据库的建立可以为相关领域研究者提供必要的数据支持,也欢迎广大研究者的使用与批评。
已有的研究发现,关于概念的各属性知识分布式表征在大脑相应区域,并且人脑存在基于感觉的和基于语言的两种概念表征系统。人们在回忆信息时也是通过语义网络的搜寻而进行的,因此,在语义上与其他词汇有更广泛连接的词更容易被记住。然而目前尚不清楚人脑如何表征概念之间的关系。目前对于概念之间关系的度量主要依据概念之间共享的特征,如果两个概念有较多的共享特征,则这两个概念就具有很高的相似性。基于这一观点,我们采用了特征产出范式(Toglia, 2009),请被试列出概念的属性,即给定一个单词,让被试对这个概念的特征进行描述,被试想到什么特征就写下什么。
本数据库共包含1410个概念,均为实体概念(名词)。共有204名被试参与本实验(男性44名)。年龄在18-57岁之间(M=23.495,SD=4.806)。所有的被试均为中国人,母语为汉语。平均每个被试完成了对202个概念的评定。本数据库中,1410个概念共得到378533个有效描述,平均每个概念获得的描述为268个,平均每个概念有37个特征。
我们还统计了哪些特征是多个概念所共有的,哪些特征是某些概念所特有的。如果某特征是3个及以上的概念都有的,则算共有特征,如果某特征只有1或2个概念拥有,则算特有特征。平均每个概念有31个共有特征,6个特有特征。
有研究表明,不同类别的物体拥有的共享特征数量不同,例如,动物类概念具有更多的共享特征(如都有眼睛、耳朵和鼻子),而工具类物体则共享特征较少而特有特征较多(Clarke & Tyler, 2015)。我们将1410个概念分成了28个小类和7个大类,并统计了每个类别的概念数量以及概念具有的共享特征数、特有特征数和特征总数,分析了不同类别的差异,发现:动物、植物、食物拥有较多的共有特征和较少的特有特征,而自然物、人造物、身体部位则拥有较多的特有特征和较少的共享特征。结果如下图所示:
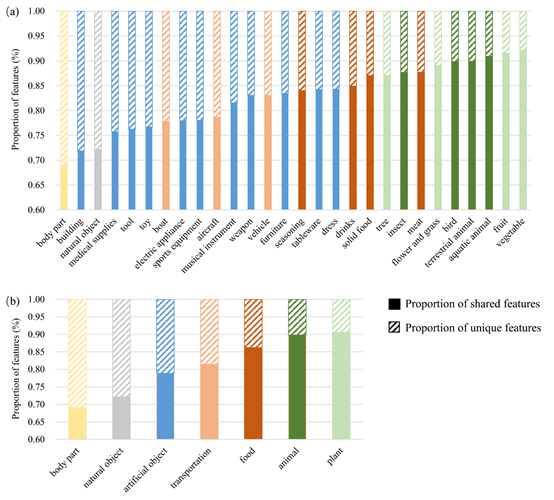
图2 各类别共有特征和特有特征所占比例
概念之间的相似度分析:
苹果和香蕉这两个概念显然要比苹果和网球这两个概念更相似,即使网球从外形上看要比香蕉更像苹果。对于概念的语义表征,我们采用余弦距离计算概念之间的距离,以此作为相似度的指标。数值越大表示概念之间的距离越近,概念相似度越高。我们对比了本数据库与目前已经被广泛使用的英文版概念语义特征数据库CSLB (Devereux, Tyler, Geertzen, & Randall, 2014)在概念相似度方面的情况。结果如图3所示。其中图3(a)是本研究的结果,图3(b)是CSLB的结果。可以看出:大类概念上基本是一致的,在某些小类之间还是有一定的差异。例如花与水果在CSLB中分的更开一些。这或许反映出文化上的一些差异。
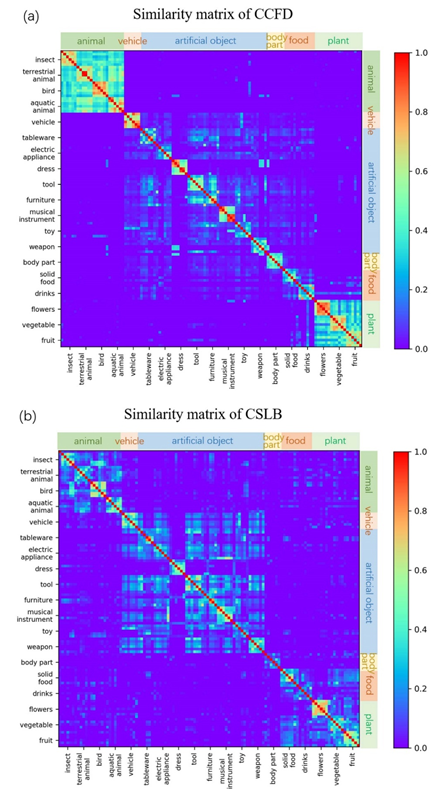
图3 概念之间的相似性矩阵
分层聚类:
本研究还基于概念的特征,对所有概念做了分层聚类。由于概念太多,无法全部可视化呈现,因此,仅可视化了动物这一大类的分层聚类结果,如下图所示。从分层聚类的结果可以看出,在动物类别下,本数据库与CSLB相似,可以很好地细分为鸟类(绿线)、昆虫类(红线)、水生动物类(紫线)和陆生动物类(青线)。
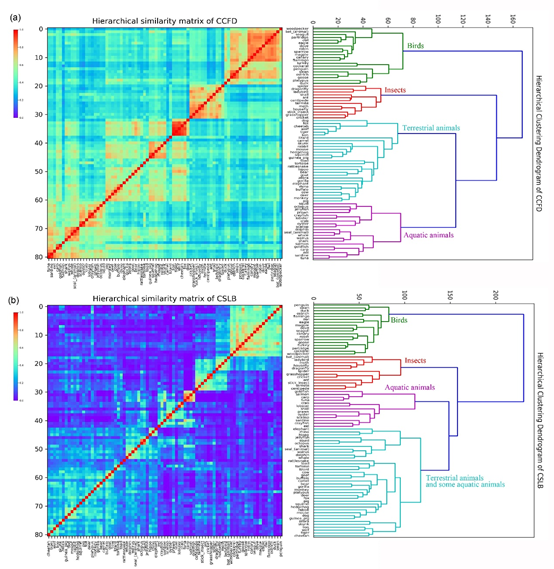
图4 动物大类分层聚类的结果
总结:
本研究建立了一个数据量上千的中文版概念语义特征数据库。共有1410个概念,都是对以汉语为母语的被试而言很熟悉的实体概念,涵盖7个大类,28个小类,平均每个概念有约37个特征。根据概念的特征计算出的概念之间的相似性分析结果显示,同一类别内的概念具有相似性,不同类别之间的概念相似性较低,但也并非完全无关。这与我们日常对事物的认识是一致的,即使是不同类别的物体,我们仍然可以以非类别的关系产生一定的关联,如经常在同一场景中出现的筷子和面条,前者属于餐具,后者属于食物。
通过与已有的标准化的英文版数据库进行各方面对比,本研究提出的CCPD无论从数据量还是质量上看,都是可观的。与英文版数据库最大的区别在于具体的概念和特征有所不同,尤其是食物这一大类有很大的区别,食物中包含一些人们非常熟悉却又非常具有文化差异的概念,如臭豆腐、皮蛋、冰糖葫芦等只有中国人才熟悉的概念,因此,这是一个更适合中文被试和中文研究的数据库。通过对比中英文的概念特征数据库,也可以系统地考察中西方的差异,包括概念的差异、相同概念的不同特征的差异等。
通过分析概念各个特征被提及的频次,可以看到哪些特征是核心特征,哪些特征是边缘特征,如何根据这些特征定义一个概念,也是语言和认知心理学家研究的重要问题。并且本数据库的数据显示,根据这些概念所具有的特征可以对概念进行分类,甚至可以按层级分类。但是人脑如何表征概念的范畴和概念的层级关系还有待探索。本数据库可以为此类研究提供数据支持。本研究还发现,不同类别的概念拥有的共享特征和特有特征的数量具有差异,自然生物,如动物、植物等概念具有更多的共享特征,而人造物,如工具等概念具有更少的共享特征,这与以往的研究结果是一致的(Clarke & Tyler, 2015)。
很多关于记忆和语言的研究会采用语义启动范式,研究者通过操纵前后呈现的两个词之间的相关程度来激发操纵启动效应,比起不相关的提示词,相关的提示词能使被试更快地识别出目标词。如何确定概念之间的相关程度,进而选择合适的启动词和目标词,是相关研究的关键。本研究通过各个特征及其权重计算了概念之间的距离,未来的语义启动范式研究可以此作为度量启动词与目标词之间相关程度的指标之一。因此,本研究为语义启动范式提供了丰富的数据支持。
在人工智能的知识图谱领域中,研究者们试图在数据库系统上利用图谱这种抽象载体来表示知识这种认知内容,从而服务于机器翻译、智能问答等领域(Balaid, Abd Rozan, Hikmi, & Memon,2016)。知识图谱数据库的概念数量相比于人为评定的数据库的概念数量大很多,但这些概念的特征通常是从互联网海量数据中抽取出来的,并采用逻辑严密的结构来表征他们之间的关系。这与人脑对概念的学习和表征不同,人脑对概念的学习并不是一次性获得并存储概念的所有特征,而是在生活中不同时刻习得概念的各个特征,而且学习的过程也分为快速学习和慢速学习两种,当新学习的内容与已有知识结构一致时,可以快速整合到新皮层已有知识中,而当与已有知识不一致时,则需要耗费较长时间在内侧颞叶皮层和海马体内进行加工,再缓慢整合到新皮层中。新皮层中分布式存储着概念的各种模态的特征,如狗的形象在视觉皮层表征,狗的叫声在听觉皮层表征,同时,关于狗的各种特征的语义表征则在前颞叶区域。虽然人脑对概念的表征不是完全精确的,但却有很强的灵活性,这也是人脑智能的重要体现。通过对人脑知识表征方式的研究,建立更类似于大脑拥有的知识图谱(我们称为类脑知识图谱),或许能为人工智能提供更好的数据基础服务。
希望通过本数据库的建立为语言学、心理学、神经科学、人工智能等领域相关研究者提供有关概念语义表征标准化的数据支持。如果大家在使用过程中发现了错误,希望您能直接联系我们,我们及时更改,为后续研究者提供更准确的数据支持。如果有对人脑概念学习和表征感兴趣的研究者,也欢迎合作交流。
近期,我团队在此基础上又构建了中文版动词语义特征数据库,相关论文目前正在审稿中。
相关代表性成果:
1.Deng Y, Wang Y, Qiu C, et al. A Chinese Conceptual Semantic Feature Dataset (CCFD)[J]. Behavior Research Methods, 2021: 1-13.
2.Wang Y*, Deng Y, Cao L, Zhang J, Yang L. Retrospective memory integration accompanies reconfiguration of neural cell assemblies [J]. Hippocampus, 2021.
3.Wang Y, Gao Y, Deng Y, et al. Modeling of Brain-Like Concept Coding with Adulthood Neurogenesis in the Dentate Gyrus[J]. Computational Intelligence and Neuroscience, 2019, 2019.