近年来,人工智能高速发展,自然语言处理、计算机视觉及机器学习等技术都取得了长足进展,在人工智能技术的渗透影响下,媒体也在经历从传统媒体到智能媒体的转型,媒体的传播载体主要是视觉、听觉信息两大类别,针对于此,我团队利用人工智能技术,针对视听类信息的处理、分析和理解开展了相关工作,尤其在元学习、视觉注意力、智能语音和视频智能创作等方面取得了许多成果。
一、元学习
机器学习研究的传统模式是利用庞大的特定任务数据集进行训练,当更换任务时,则需要重新训练模型,显然,这与人类如何利用过去的经验快速学习新任务相去甚远。元学习(Meta-learning)是过去几年最火爆的学习方法之一,它的目的是让模型学会学习,以缓解调参量巨大和学习新任务重新训练带来的计算成本问题。元学习最知名的应用领域是小样本学习,除此之外,很多学者也将元学习应用到超参优化、神经网络结构搜索、人工智能可信赖性等问题中。
我们使用元学习,在人脸防伪、图像对抗攻击等方面开展了人工智能可信赖性相关的研究,并取得了不错的成果。
人脸识别是计算机视觉中最为广泛的应用,而人脸防伪则保护着人脸识别系统的安全性,因此人脸防伪研究是人工智能的可信赖性领域的一个重要分支。现有的人脸防伪方法通常使用人工定义的二分类标签或者逐像素的标签来监督人脸防伪模型的训练。然而,人工定义的标签在监督人脸防伪模型方面并不是最优的。我院教师提出了一种非常新颖的元教师方法来更好的监督人脸防伪模型,提出了一种二阶优化框架来训练该元教师学习如何监督人脸防伪模型习得尽可能丰富的假人脸线索(如图1)。

图1 二阶优化框架示意图
在5个人脸防伪测试标准上的大量实验证明,相比于人工定义的标签以及现有的教师-学生方法,我们所提出的元教师方法的确可以更好地监督人脸防伪模型,从而使得人脸防伪模型的性能得到提高,并取得超越所有现有方法的人脸防伪性能。
另外,神经网络的鲁棒性也是人工智能可信赖性的一个研究分支,众所周知,当我们给图像/视频加入特定噪音,神经网络则会对其预测出错,甚至一段胶带,就能让自动驾驶系统把停止标志认成限速45(如图2),产生致命错误,而这种加入特定噪音的图像/视频使得神经网络出错的方法就叫对抗攻击。

图2 图片源自参考文献[1]
我们针对神经网络的鲁棒性进行了图像对抗攻击的研究工作,提出了一个新的框架:元迁移攻击(Meta-transfer attack),该框架利用代理模型训练了一个元代理模型, 经过大量实验证明,在该模型上生成的对抗样本具有较好的可迁移性,可以被用来攻击其它神经网络,并几乎所有图像分类测试场景下都取得了历史最佳的性能表现,相关文章已投稿。
二、视觉注意力
人工智能的目标是让机器具有类似人类的某些能力,而视觉注意力本质是为了让机器模仿人类的观察方式,排除干扰、关注感兴趣的区域。因此视觉注意力机制的研究,是一个将人类视觉系统认知原理应用到计算机科学领域的交叉性研究热点,得到了学术界大量关注。作为脑科学与智能媒体研究院,我团队的脑科学、认知神经科学基础对计算机领域视觉注意力的研究十分有利。
现有的基于深度学习的视觉注意力预测模型, 主要依赖于大规模的人类眼动数据集, 来训练模型去拟合从视觉输入刺激到视觉注意力的高维映射. 这类全监督数据驱动的方法需要大量繁重的标注, 并且没有考虑到视觉注意力的根本机制。
我院教师基于各种视觉注意力的认知原理, 提出的视觉注意力模型, 将从认知科学中得到的启示建模成可微分的子模块, 从而得到一个统一的、端到端可训练的网络框架. 此外, 我们提出了新颖的损失函数, 从图像语意、显著性先验知识、自信息压缩三个来源获取监督信息. 实验表面, 我们的方法取得了有希望的结果, 甚至超过了许多全监督的深度学习算法. 我们的方法不仅在减少数据标注依赖方向上迈进了一大步, 而且提供了对视觉注意力机制更全面的理解;
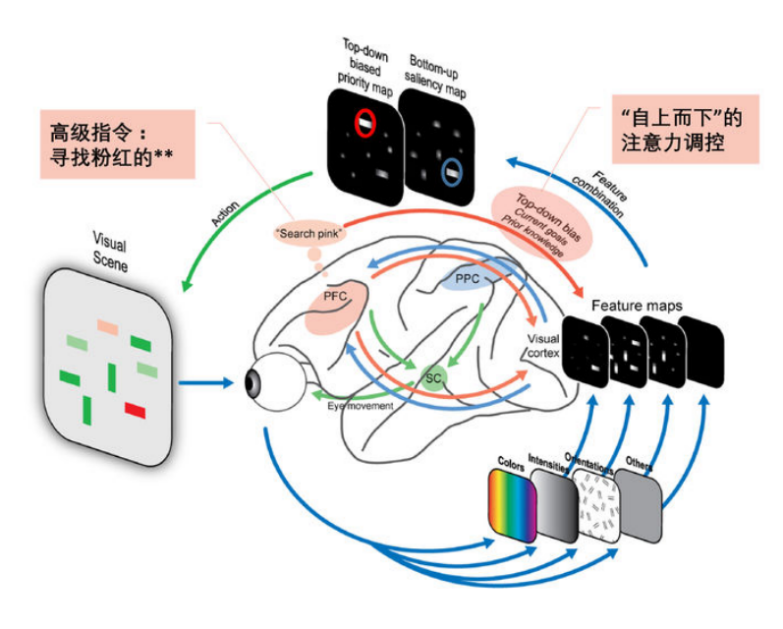
图3 注意力生理机制演示图(图片源自参考文献[2])
另外,受启发于人类视觉系统中存在的选择性注意力机制,这种选择性机制起到“信息瓶颈 (information bottleneck)”的作用, 它能在信息压缩和感知精度达到平衡;我院教师提出了一种基于信息瓶颈的空间注意力机制, 从信息瓶颈的目标函数出发, 推导、设计出了一个框架, 并且在图像识别任务中, 验证了这种空间注意力机制的有效性。
三、智能语音
语音是人类连接智能设备的重要方式,智能语音是AI的核心技术之一,也是落地最早的技术之一,相关技术经过三个阶段的发展,目前已进入落地期,移动及车载智能语音助手、智能音箱相继产品化,为人们的生活提供了诸多便捷。
借鉴大脑神经机制是智能语音技术攻克技术瓶颈的重要途径,我院在脑启发的声源定位与生成、语音识别与评测、个性化HRTF生成与定位、鸡尾酒会问题等方面开展了全面研究。
目前在研的项目包括数学工程与先进计算国家重点实验室开放基金课题《仿脑 SNN对自然声波的编码与重建研究》,该项目将探索并提出基于仿脑脉冲神经网络(SNN)对自然声波的编码与重建方法;教育部项目《基于<标准>的国际中文智能语音学习APP开发与资源建设》,该项目将研究脑启发的语音识别与评测技术,并开发主要面向海外的中文教学APP,提供语音教学、普通话评测、语音社交等功能。
四、视频智能创作
研究院和北京协同创新研究院于2015年创建智能传媒技术中心,由我院院长曹立宏教授担任中心主任。智能传媒技术中心立项“视频智能创作平台及示范应用”项目,聚集了我校多个核心团队、充分发挥我校在传媒技术领域的优势,展开“产学研“合作,研发完成了音视频智能标注系统、视频智能创作平台和交互场景制播平台,转化技术为市场服务。
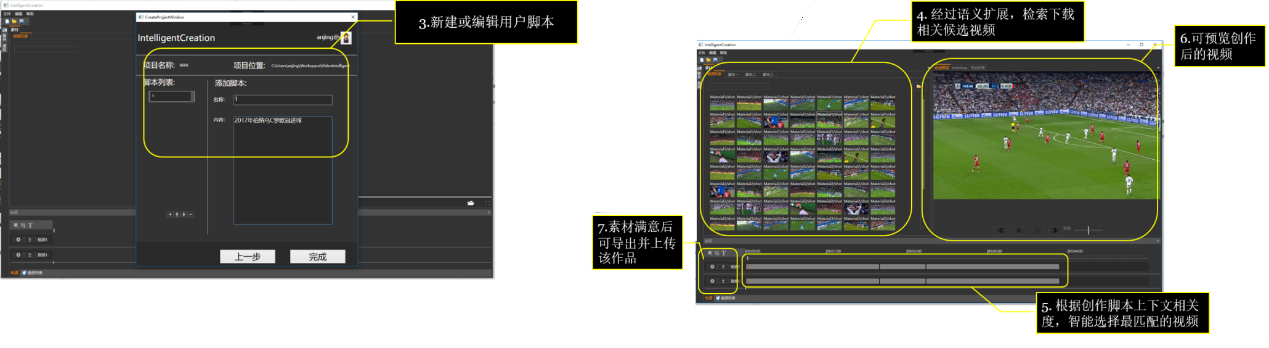
图4 视频智能创作平台
视频智能创作平台,可以依据用户创作需求(文本形式输入),平台进行语义分析,自动检索,通过音视频智能标注系统,获取视频素材,智能匹配,形成新视频。用户可以进一步调整。
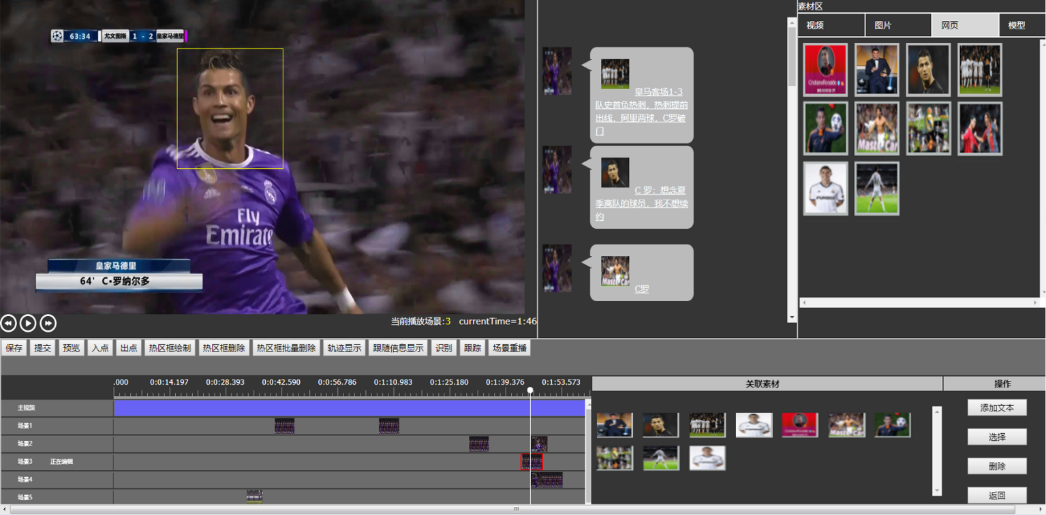
图5 交互场景制播平台
交互场景制播平台,可自动检测或人工选择视频中的人物、物体内容,添加链接信息(相关内容或广告等),添加交互场景;用户可以在PC、手机和VR设备观看具有交互特征的视频。
五、智能医疗
除此上述介绍的相关科研工作外,我们还将人工智能技术应用到了智能医疗领域。2015-2017年,我团队与首都医科大学附属北京友谊医院、北京华信佳音科技发展有限公司合作,基于深度学习和图像处理算法研发了“人工智能内镜下精准识别辅助诊断系统”,辅助医生对消化系统病变进行诊断。在前期研究中,已建立起系统、规范、高质量、点对点、涵盖多种消化道病变的内镜图片数据库,并依托国家消化系统疾病临床医学研究中心先后开展了三次不同规模的人机对比测试。
最终,该成果在2017年中国消化内镜学术大会的“消化道病变内镜图片判读人机竞技交流会”上战胜参加活动的各个级别医生,以较大优势取得了全面胜利。
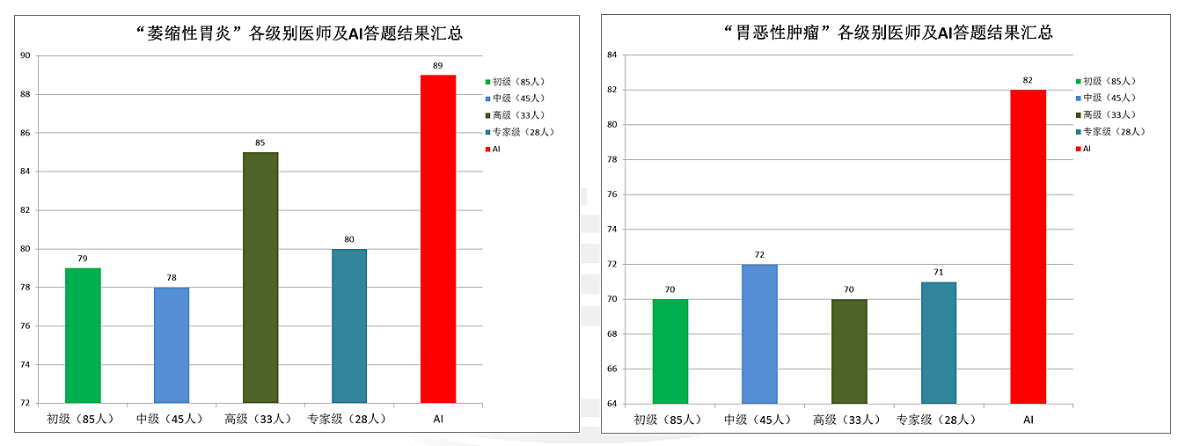
图6 人机对战结果
在此次人机读片交流竞技中,AI“0.2秒/张的病变识别速度、接近90%的识别正确率”充分展现了其对于萎缩性胃炎、胃恶性肿瘤两种病变内镜图片初步学习取得的明显成果。尤其在胃恶性肿瘤图片判读中,AI的正确率更是超过了在场92%的消化内镜医师,充分说明了人工智能在医疗领域的应用潜力及广阔前景。
[1]Heaven D. Why deep-learning AIs are so easy to fool[J]. Nature, 2019, 574(7777): 163-166.
[2] Katsuki F, Constantinidis C. Bottom-up and top-down attention: different processes and overlapping neural systems[J]. The Neuroscientist, 2014, 20(5): 509-521.
相关代表性成果:
1.Yunxiao Qin, Zitong Yu, Longbin Yan, Chenxu Zhao, Zezheng Wang, Zhen Lei, Meta-Teacher for Face Anti-Spoofing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2021. 中科院SCI一区,CCF-A, IF=16.39.
2.Yunxiao Qin, Yuanhao Xiong, Jinfeng Yi, Cho-Jui Hsieh. Training meta-surrogate model for transferable adversarial attack [J]. Submitted to NIPS-2022.
3.Qiuxia Lai, Tianfei Zhou, Salman Khan, Hanqiu Sun, Jianbing Shen, & Ling Shao. Weakly Supervised Visual Saliency Prediction. IEEE TIP, 31: 3111-3124, 2022.
4.Qiuxia Lai, Yu Li, Ailing Zeng, Minhao Liu, Qiang Xu, & Hanqiu Sun. Information Bottleneck Approach to Spatial Attention Learning. IJCAI, 2021.
5.曹立宏,第七届中国国际“互联网+”大学生创新创业大赛优秀指导教师奖(指导学生获国家铜奖、北京赛区复赛三等奖等奖项),2021.
6.张佳鸿,2021年华为杯第18届中国研究生数学建模竞赛三等奖,2021.
7.Wu J, Li Y. Research on construction of semantic dictionary in the football field[C]//2017 IEEE 15th International Conference on Software Engineering Research, Management and Applications (SERA). IEEE, 2017: 303-306.
8.Zhou X, Gong W, Fu W L, et al. Application of deep learning in object detection[C]//2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS). IEEE, 2017: 631-634.
9.Feng C, Yu P, Yu S, et al. The research on segmentation methods of soccervideoes[C]//2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS). IEEE, 2017: 645-648.
10.[软件著作权]场景媒体智能交互编辑系统
11.[软件著作权]视频智能创作与编辑软件人机交互系统
12.[专利]陈雯婕,伏文龙,曹立宏.一种视频动作分类的处理方法及装置. CN201710573692.2